![]()
![]()
![]()
![]()
![]()
UNIX Unleashed, Internet Edition
![]()
![]()
![]()
![]()
![]()
by Robin Burk and James Armstrong
UNIX shells support a wide range of commands that can be combined, in the form of scripts, into reusable programs. Command scripts for shell programs (and utilities such as Awk and Perl) are all the programming that many UNIX users need to be able to customize their computing environment.
Script languages have several shortcomings, however. To begin with, the commands that the user types into a script are only read and evaluated when the script is being executed. Interpreted languages are flexible and easy to use, but they are also inefficient because the commands must be reinterpreted each time the script is executed, and they are ill-suited to manipulate the computer's memory and I/O devices directly. Therefore, the programs that process scripts (such as the various UNIX shells, the Awk utility, and the Perl interpreter) are themselves written in the C and C++ languages, as is the UNIX kernel.
Many users find learning a scripted, interpreted language fairly easy because the commands can usually be tried out one at a time, with clearly visible results. Learning a language like C or C++ is more complex and difficult because the programmer must learn to think in terms of machine resources and the way in which actions are accomplished within the computer rather than in terms of user-oriented commands.
This chapter introduces you to the basic concepts of C and C++, and demonstrates how to build some simple programs. Even if you do not go on to learn how to program extensively in either language, you will find that the information in this chapter will help you to understand how kernels are built and why some of the other features of UNIX work the way they do. If you are interested in learning more about C and C++, I recommend the following books from Sams Publishing:
C is the programming language most frequently associated with UNIX. Since the 1970s, the bulk of the operating system and applications have been written in C. Because the C language does not directly rely on any specific hardware architecture, UNIX was one of the first portable operating systems. That is, the bulk of the code that makes up UNIX neither knows nor cares about the actual computer on which it is running. Machine-specific features are isolated in a few modules within the UNIX kernel, making it easy to modify these modules when you're porting to a different hardware architecture.
C was first designed by Dennis Ritchie for use with UNIX on DEC PDP-11 computers. The language evolved from Martin Richard's BCPL, and one of its earlier forms was the B language, which was written by Ken Thompson for the DEC PDP-7. The first book on C was The C Programming Language by Brian Kernighan and Dennis Ritchie, published in 1978.
In 1983, the American National Standards Institute (ANSI) established a committee to standardize the definition of C. Termed ANSI C, it is the recognized standard for the language grammar and a core set of libraries. The syntax is slightly different from the original C language, which is frequently called K&R C--for Kernighan and Ritchie. This chapter primarily addresses ANSI C.
C is a compiled, third-generation procedural language. Compiled means that C code is analyzed, interpreted, and translated into machine instructions at some time prior to the execution of the C program. These steps are carried out by the C compiler and, depending on the complexity of the C program, by the make utility. After the program is compiled, it can be executed many times without recompilation.
The phrase third-generation procedural describes computer languages that clearly distinguish the data used in a program from the actions performed on that data. Programs written in third-generation languages take the form of a series of explicit processing steps, or procedures, which manipulate the contents of data structures by means of explicit references to their location in memory, and which manipulate the computer's hardware in response to hardware interrupts.
In the C language, all procedures take the form of functions. Just as a mathematical function transforms one or more numbers into another number, so too a C function is typically a procedure that transforms some value or performs some other action and returns the results. The act of invoking the transformation is known as calling the function.
Mathematical function calls can be nested, as can function calls in C. When function calls are nested, the results of the innermost function are passed as input to the next function, and so on. Figure 6.1 shows how nested calls to the square root function are evaluated arithmetically.
| Function | Value |
| sqrt(256) | 16 |
| sqrt( sqrt(256) ) = sqrt(16) | 4 |
| sqrt( sqrt( sqrt(256) ) ) = sqrt(4) = | 2 |
Figure 6.1.
Nested operations in mathematics.
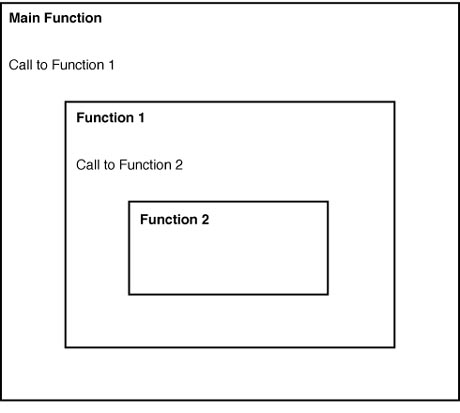
Figure 6.2 shows the way that function calls are nested within C programs. In the figure, the Main function calls Function 1, which calls Function 2. Function 2 is evaluated first, and its results are passed back to Function 1. When Function 1 completes its operations, its results are passed back to the Main function.
Figure 6.2.
Nesting function calls within C programs.
Non-functional procedures in other languages often operate on data variables that are shared with other code in the program. For example, a non-functional procedure might update a program-wide COUNT_OF_ERRORS whenever a user makes a keyboard mistake. Such procedures must be carefully written, and they usually are specific to the program for which they first were created because they reference specific, shared data variables within the wider program.
A function, however, receives all the information it needs (including the location of data variables to use in each instance) when it is called. It neither knows nor cares about the wider program context that calls it; it simply transforms the values found within the input variables (parameters), whatever they might be, and returns the result to whatever other function invoked it.
Because they are implemented as functions, procedures written in C do not need to know whether, or how deeply, they will be nested inside other function calls. This capability allows you to reuse C functions in many different programs without modifying them. For example, Function 2 in Figure 6.2. might be called directly by the Main logic in a different C program.
An entire C program is itself a function that returns a result code, when executed, to the program that invoked it. It is usually a shell in the case of applications but might also be any other part of the operating system or any other UNIX program. Because C programs are all structured as functions, they can be invoked by other programs or nested inside larger programs without your needing to rewrite them in any way.
NOTE: This feature of C has heavily shaped the look and feel of UNIX. More than in most other operating environments, UNIX systems consist of many small C programs that call one another, are combined into larger programs, or get invoked by the user as needed. Rather than use monolithic, integrated applications, UNIX typically hosts many small, flexible programs. You can customize your working environment by combining these tools to do new tasks.
The data that is manipulated within C programs is of two sorts: literal values and variables. Literal values are specific, actual numbers or characters, such as 1, 4.35, or a.
Variables are names associated with a place in memory that can hold data values. Each variable in C is typed; that is, each variable can hold only one kind of value. The basic data types include integers, floating point (real) numbers, characters, and arrays. An array is a series of data elements of the same type, in which the elements are identified by the order (place) within the series.
You can define complex data structures as well. Complex data structures are used to gather a number of related data items together under one name. A terminal communications program, for example, might have a terminal control block (TCB)associated with each user who is logged on. The TCB typically contains data elements identifying the communications port, active application process, and other information associated with that terminal session.
You must explicitly define all variables in a C program before you can use the variables.
The development of a C program is an iterative procedure. Many UNIX tools are involved in this four-step process. They are familiar to software developers:
You repeat the first two steps until the program compiles successfully. Then the execution and debugging begin. Many of the concepts presented here may seem strange to non-programmers. This chapter endeavors to introduce C as a programming language.
The typical first C program is almost a cliché. It is the "Hello, World" program, and it prints the simple line Hello, World. Listing 6.1 shows the source of the program.
main()
{
printf("Hello, World\n");
}
You can compile and execute this program as follows:
$ cc hello.c $ a.out Hello, World $
You compile the program by using the cc command, which creates a program a.out if the code is correct. Just typing a.out runs the program. The program includes only one function, main. Every C program must have a main function; it is the place where the program's execution begins. The only statement is a call to the printf library function, which passes the string Hello, World\n. (Functions are described in detail later in this chapter.) The last two characters of the string, \n, represent the carriage return-line feed character.
As with all programming languages, C programs must follow rules. These rules describe how a program should appear and what those words and symbols mean. These rules create the syntax of a programming language. You can think of a program as a story. Each sentence must have a noun and a verb. Sentences form paragraphs, and the paragraphs tell the story. Similarly, C statements can build into functions and programs.
Like all languages, C deals primarily with the manipulation and presentation of data. BCPL deals with data as data. C, however, goes one step further to use the concept of data types. The basic data types are character, integer, and floating point numbers. Other data types are built from these three basic types.
Integers are the basic mathematical data type. They can be classified as long and short integers, and the size is implementation-dependent. With a few exceptions, integers are four bytes in length, and they can range from -2,147,483,648 to 2,147,483,647. In ANSI C, you define these values in a header--limit.h--as INT_MIN and INT_MAX. The qualifier unsigned moves the range one bit higher, to the equivalent of INT_MAX-INT_MIN.
Floating point numbers are used for more complicated mathematics. Integer mathematics is limited to integer results. With integers, 3/2 equals 1. Floating point numbers give a greater amount of precision to mathematical calculations: 3/2 equals 1.5. Floating point numbers can be represented by a decimal number, such as 687.534, or with scientific notation, such as 8.87534E+2. For larger numbers, scientific notation is preferred. For even greater precision, the type double provides a greater range. Again, specific ranges are implementation-dependent.
Characters are usually implemented as single bytes, although some international character sets require two or more bytes. The most common set of character representations is ASCII, found on most U.S. computers.
An array is used for a sequence of values that are often position-dependent. An array is useful when you need a range of values of a given type. Related to the array is the pointer. Variables are stored in memory, and a pointer is the physical address of that memory. In a sense, a pointer and an array are similar, except when a program is invoked. The space needed for the data of an array is allocated when the routine that needs the space is invoked. For a pointer, the space must be allocated by the programmer, or the variable must be assigned by dereferencing a variable. (To dereference means to ask the system to return the address of a variable.) You use the ampersand to indicate dereferencing, and you use an asterisk when the value pointed at is required. Here are some sample declarations:
| int i; | Declares an integer |
| char c; | Declares a character |
| char *ptr; | Declares a pointer to a character |
| double temp[16]; | Declares an array of double-precision floating point numbers with 16 values |
Listing 6.2 shows an example of a program with pointers.
int i;
int *ptr;
i=5;
ptr = &i;
printf("%d %x %d\n", i,ptr,*ptr);
output is: 5 f7fffa6c 5
NOTE: A pointer is just a memory address and tells you the address of any variable.
A string has no specific type. You use an array of characters to represent strings. You can print them by using an %s flag instead of %c.
Simple output is created by the printf function. printf takes a format string and the list of arguments to be printed. A complete set of format options is presented in Table 6.1. You can modify format options with sizes. Check the documentation for the full specification.
| Conversion | Meaning |
| %% | Percentage sign |
| %E | Double (scientific notation) |
| %G | Double (format depends on value) |
| %X | Hexadecimal (letters are capitalized) |
| %c | Single character |
| %d | Integer |
| %e | Double (scientific notation) |
| %f | Double of the form mmm.ddd |
| %g | Double (format depends on value) |
| %i | Integer |
| %ld | Long integer |
| %n | Count of characters written in current printf |
| %o | Octal |
| %p | Print as a pointer |
| %s | Character pointer (string) |
| %u | Unsigned integer |
| %x | Hexadecimal |
Some characters cannot be included easily in a program. New lines, for example, require a special escape sequence because an unescaped newline cannot appear in a string. Table 6.2 contains a complete list of escape sequences.
| Escape Sequence | Meaning |
| \" | Double quotation mark |
| \' | Single quotation mark |
| \? | Question mark |
| \\ | Backslash |
| \a | Audible bell |
| \b | Backspace |
| \f | Form feed (new page) |
| \n | New line |
| \ (followd by digits 000) | Octal number |
| \r | Carriage return |
| \t | Horizontal tab |
| \v | Vertical tab |
| \xhh | Hexadecimal number |
A full program is compilation of statements. Statements are separated by semicolons. You can group them in blocks of statements surrounded by curly braces. The simplest statement is an assignment. A variable on the left side is assigned the value of an expression on the right.
At the heart of the C programming language are expressions. They are techniques to combine simple values into new values. The three basic types of expressions are comparison, numerical, and bitwise expressions.
The simplest expression is a comparison. A comparison evaluates to a TRUE or a FALSE value. In C, TRUE is a non-zero value, and FALSE is a zero value. Table 6.3 contains a list of comparison operators.
| Operator | Meaning | Operator | Meaning |
| < | Less than | >= | Greater than or equal to |
| > | Greater than | || | Or |
| == | Equal to | && | And |
| <= | Less than or equal to |
You can build expressions by combining simple comparisons with ANDs and ORs to make complex expressions. Consider the definition of a leap year. In words, it is any year divisible by 4, except a year divisible by 100 unless that year is divisible by 400. If year is the variable, you can define a leap year with the following expression:
((((year%4)==0)&&((year%100)!=0))||((year%400)==0))
On first inspection, this code might look complicated, but it isn't. The parentheses group the simple expressions with the ANDs and ORs to make a complex expression.
One convenient aspect of C is that you can treat expressions as mathematical values, and you can use mathematical statements in expressions. In fact, any statement--even a simple assignment--has values that you can use in other places as an expression.
The mathematics of C is straightforward. Barring parenthetical groupings, multiplication and division have higher precedence than addition and subtraction. The operators, which are listed in Table 6.4, are standard.
| Operator | Meaning | Operator | Meaning |
| + | Addition | / | Division |
| - | Subtraction | % | Integer remainder |
| * | Multiplication | ^ | Exponentiation |
You also can use unary operators, which affect a single variable. They are ++ (increment by one) and -- (decrement by one). These shorthand versions are quite useful.
You also can use shorthands for situations in which you want to change the value of a variable. For example, if you want to add an expression to a variable called a and assign the new value to a, the shorthand a+=expr is the same as a=a+expr. The expression can be as complex or as simple as required.
NOTE: Most UNIX functions take advantage of the truth values and return 0 for success. This way, a programmer can write code such asif (function()) { error condition}The return value of a function determines whether the function worked.
Because a variable is just a string of bits, many operations work on these bit patterns. Table 6.5 lists the bit operators.
| Operator | Meaning | Operator | Meaning |
| & | Logical AND | << | Bit shift left |
| | | Logical OR | >> | Bit shift right |
A logical AND compares the individual bits in place. If both are 1, the value 1 is assigned to the expression. Otherwise, 0 is assigned. For a logical OR, 1 is assigned if either value is a 1. Bit shift operations move the bits a number of positions to the right or left. Mathematically, this process is similar to multiplying or dividing by 2, with the difference that you can apply bit shifting to non-numeric data types, and shifting may cause the loss of information in bits that are lost "off the end" of the variable. Bit operations are often used for masking values and for comparisons. A simple way to determine whether a value is odd or even is to perform a logical AND with the integer value 1. If it is TRUE, the number is odd.
With what you've seen so far, you can create a list of statements that are executed only once, after which the program terminates. To control the flow of commands, you can use three types of loops that exist in C. The simplest is the while loop. The syntax is
while (expression)
statement
As long as the expression between parentheses evaluates as non-zero--or TRUE in C--the statement is executed. The statement actually can be a list of statements blocked off with curly braces. If the expression evaluates to zero the first time it is reached, the statement is never executed. To force at least one execution of the statement, use a do loop. The syntax for a do loop is
do
statement
while (expression);
The third type of control flow is the for loop, which is more complicated. The syntax is
for(expr1;expr2;expr3) statement
When the expression is reached for the first time, expr1 is evaluated. Next, expr2 is evaluated. If expr2 is non-zero, the statement is executed, followed by expr3. Then expr2 is tested again, followed by the statement and expr3, until expr2 evaluates to zero. Strictly speaking, this use is a notational convenience because you can structure a while loop to perform the same actions. Here's an example:
expr1;
while (expr2) {
statement;
expr3
}
Loops can be interrupted in three ways. A break statement terminates execution in a loop and exits it. continue terminates the current iteration and retests the loop before possibly re-executing the statement. For an unconventional exit, you can use goto. goto changes the program's execution to a labeled statement. According to many programmers, using goto is poor programming practice, so you should avoid using it.
Statements can also be executed conditionally. Again, you can use three different formats for statement execution. The simplest is an if statement. The syntax is
if (expr) statement
If the expression expr evaluates to non-zero, the statement is executed. You can expand this statement with an else, the second type of conditional execution. The syntax for else is
if (expr) statement else statement
If the expression evaluates to zero, the second statement is executed.
NOTE: The second statement in an else condition can be another if statement. This situation might cause the grammar to be indeterminate if the structureif (expr) if (expr) statement else statementis not parsed cleanly.
As the code is written, the else is considered applicable to the second if. To make it applicable with the first if, you can surround the second if statement with curly braces, as in this example:
$ if (expr) {if (expr) statement} else statement
The third type of conditional execution is more complicated. The switch statement first evaluates an expression. Then it looks down a series of case statements to find a label that matches the expression's value and executes the statements following the label. A special label default exists if no other conditions are met. If you want only a set of statements executed for each label, you must use the break statement to leave the switch statement.
You've now covered the simplest building blocks of a C program. You can add more power by using functions and by declaring complex data types.
If your program requires different pieces of data to be grouped on a consistent basis, you can group them into structures. Listing 6.3 shows a structure for a California driver's license. Note that it includes integer, character, and character array (string) types.
struct license {
char name[128];
char address[3][128];
int zipcode;
int height, weight, month, day, year;
char license_letter;
int license_number;
};
struct license newlicensee;
struct license *user;
Because California driver's license numbers consist of a single character followed by a seven-digit number, the license ID is broken into two components. Similarly, the newlicensee's address is broken into three lines, represented by three arrays of 128 characters.
Accessing individual fields of a structure requires two different techniques. To read a member of a locally defined structure, you append a dot to the variable and then the field name, as shown in this example:
newlicensee.zipcode=94404;
To use a pointer, to the structure, you need -> to point to the member:
user->zipcode=94404;
Here's an interesting note: If the structure pointer is incremented, the address is increased not by 1, but by the size of the structure.
Using functions is an easy way to group statements and to give them a name. They are usually related statements that perform repetitive tasks such as I/O. printf, described previously, is a function. It is provided with the standard C library. Listing 6.4 illustrates a function definition, a function call, and a function.
NOTE: The ellipsis simply means that some lines of sample code are not shown here to save space.
int swapandmin( int *, int *); /* Function declaration */
...
int i,j,lower;
i=2; j=4;
lower=swapandmin(&i, &j); /* Function call */
...
int swapandmin(int *a,int *b) /* Function definition */
{
int tmp;
tmp=(*a);
(*a)=(*b);
(*b)=tmp;
if ((*a)<(*b)) return(*a);
return(*b);
}
ANSI C and K&R C differ most in function declarations and calls. ANSI requires that function arguments be prototyped when the function is declared. K&R C required only the name and the type of the returned value. The declaration in Listing 6.4 states that the function swapandmin takes two pointers to integers as arguments and that it will return an integer. The function call takes the addresses of two integers and sets the variable named lower with the return value of the function.
When a function is called from a C program, the values of the arguments are passed to the function. Therefore, if any of the arguments will be changed for the calling function, you can't pass only the variable; you must pass the address, too. Likewise, to change the value of the argument in the calling routine of the function, you must assign the new value to the address.
In the function in Listing 6.4, the value pointed to by a is assigned to the tmp variable. b is assigned to a, and tmp is assigned to b. *a is used instead of a to ensure that the change is reflected in the calling routine. Finally, the values of *a and *b are compared, and the lower of the two is returned.
If you included the line
printf("%d %d %d",lower,i,j);
after the function call, you would see 2 4 2 on the output.
This sample function is quite simple, and it is ideal for a macro. A macro is a technique used to replace a token with different text. You can use macros to make code more readable. For example, you might use EOF instead of (-1) to indicate the end of a file. You can also use macros to replace code. Listing 6.5 is basically the same as Listing 6.4 except that it uses macros.
#define SWAP(X,Y) {int tmp; tmp=X; X=Y; Y=tmp; }
#define MIN(X,Y) ((X<Y) ? X : Y )
...
int i,j,lower;
i=2; j=4;
SWAP(i,j);
lower=MIN(i,j);
When a C program is compiled, macro replacement is one of the first steps performed. Listing 6.6 illustrates the result of the replacement.
int i,j,lower;
i=2; j=4;
{int tmp; tmp=i; i=j; j=tmp; };
lower= ((i<j) ? i : j );
The macros make the code easier to read and understand.
For your first program, write a program that prints a chart of the first 10 integers and their squares, cubes, and square roots.
Using the text editor of your choice, enter all the code in Listing 6.7 and save it in a file called sample.c.
#include <stdio.h>
#include <math.h>
main()
{
int i;
double a;
for(i=1;i<11;i++)
{
a=i*1.0;
printf("%2d. %3d %4d %7.5f\n",i,i*i,i*i*i,sqrt(a));
}
}
The first two lines are header files. The stdio.h file provides the function definitions and structures associated with the C input and output libraries. The math.h file includes the definitions of mathematical library functions. You need it for the square root function.
The main loop is the only function that you need to write for this example. It takes no arguments. You define two variables. One is the integer i, and the other is a double-precision floating point number called a. You wouldn't have to use a, but you can for the sake of convenience.
The program is a simple for loop that starts at 1 and ends at 11. It increments i by 1 each time through. When i equals 11, the for loop stops executing. You also could have written i<=10 because the expressions have the same meaning.
First, you multiply i by 1.0 and assign the product to a. A simple assignment would also work, but the multiplication reminds you that you are converting the value to a double-precision floating point number.
Next, you call the print function. The format string includes three integers of widths 2, 3, and 4. After the first integer is printed, you print a period. Next, you print a floating point number that is seven characters wide with five digits following the decimal point. The arguments after the format string show that you print the integer, the square of the integer, the cube of the integer, and the square root of the integer.
To compile this program using the C compiler, enter the following command:
cc sample.c -lm
This command produces an output file called a.out. This is the simplest use of the C compiler. cc is one of the most powerful and flexible commands on a UNIX system.
A number of different flags can change the compiler's output. These flags are often dependent on the system or compiler. Some flags are common to all C compilers. They are described in the following paragraphs.
The -o flag tells the compiler to write the output to the file named after the flag. The cc -o sample sample.c command, for example, would put the program in a file named sample.
NOTE: The output discussed here is the compiler's output, not the sample program. Compiler output is usually the program, and in every example here, it is an executable program.
The -g flag tells the compiler to keep the symbol table (the data used by a program to associate variable names with memory locations), which is necessary for debuggers. Its opposite is the -O flag, which tells the compiler to optimize the code--that is, to make it more efficient. You can change the search path for header files by using the -I flag, and you can add libraries by using the -l and -L flags.
The compilation process takes place in several steps, as you can see here:
The output from this program appears in Listing 6.8.
$ sample.c 1. 1 1 1.00000 2. 4 8 1.41421 3. 9 27 1.73205 4. 16 64 2.00000 5. 25 125 2.23607 6. 36 216 2.44949 7. 49 343 2.64575 8. 64 512 2.82843 9. 81 729 3.00000 10. 100 1000 3.16228
NOTE: To execute a program, just type its name at a shell prompt. The output will immediately follow.
You can break C programs into any number of files, as long as no function spans more than one file. To compile this program, you compile each source file into an intermediate object before you link all the objects into a single executable. The -c flag tells the compiler to stop at this stage. During the link stage, all the object files should be listed on the command line. Object files are identified by the .o suffix.
If several different programs use the same functions, you can combine them in a single library archive. You use the ar command to build a library. When you include this library on the compile line, the archive is searched to resolve any external symbols. Listing 6.9 shows an example of building and using a library.
cc -c sine.c cc -c cosine.c cc -c tangent.c ar c libtrig.a sine.o cosine.o tangent.o cc -c mainprog.c cc -o mainprog mainprog.o libtrig.a
Large applications can require hundreds of source code files. Compiling and linking these applications can be a complex and error-prone task all its own. The make utility is a tool that helps developers organize the process of building the executable form of complex applications from many source files. Chapter 7, "The make Utility," discusses the make utility in detail.
Debugging is a science and an art unto itself. Sometimes, the simplest tool--the code listing--is best. At other times, however, you need to use other tools. Three of these tools are lint, prof, and sdb. Other available tools include escape, cxref, and cb. Many UNIX commands have debugging uses.
lint is a command that examines source code for possible problems. The code might meet the standards for C and compile cleanly, but it might not execute correctly. Two things checked by lint are type mismatches and incorrect argument counts on function calls. lint uses the C preprocessor, so you can use similar command-like options as you would use for cc.
You use the prof command to study where a program is spending its time. If a program is compiled and linked with -p as a flag, when it executes, a mon.out file is created with data on how often each function is called and how much time is spent in each function. This data is parsed and displayed with prof. An analysis of the output generated by prof helps you determine where performance bottlenecks occur. Although optimizing compilers can speed your programs, this analysis significantly improves program performance.
The third tool is sdb--a symbolic debugger. When you compile a program using -g, the symbol tables are retained, and you can use a symbolic debugger to track program bugs. The basic technique is to invoke sdb after a core dump and get a stack trace. This trace indicates the source line where the core dump occurred and the functions that were called to reach that line. Often, this information is enough to identify the problem. It is not the limit of sdb, though.
sdb also provides an environment for debugging programs interactively. Invoking sdb with a program enables you to set breakpoints, examine variable values, and monitor variables. If you suspect a problem near a line of code, you can set a breakpoint at that line and run the program. When the line is reached, execution is interrupted. You can check variable values, examine the stack trace, and observe the program's environment. You can single-step through the program, checking values. You can resume execution at any point. By using breakpoints, you can discover many of the bugs in your code that you've missed.
cpp is another tool that you can use to debug programs. It performs macro replacements, includes headers, and parses the code. The output is the actual module to be compiled. Normally, though, the programmer never executes cpp directly. Instead, it is invoked through cc with either an -E or -P option. -E puts the output directly to the terminal; -P makes a file with an .i suffix.
If C is the language most associated with UNIX, C++ is the language that underlies most graphical user interfaces available today.
C++ was originally developed by Dr. Bjarne Stroustrup at the Computer Science Research Center of AT&T's Bell Laboratories (Murray Hill, New Jersey), also the source of UNIX itself. Dr. Stroustrup's original goal was to create an object-oriented simulation language. The availability of C compilers for many hardware architectures convinced him to design the language as an extension of C, allowing a preprocessor to translate C++ programs into C for compilation.
After the C language was standardized by a joint committee of the American National Standards Institute (ANSI) and the International Standards Organization (ISO) in 1989, a new joint committee began the effort to formalize C++ as well. This effort has produced several new features and refined significantly the interpretation of other language features, but it has not yet resulted in a formal language standard.
C++ is an object-oriented extension to C. Because C++ is a superset of C, C++ compilers compile C programs correctly, and you can write non-object-oriented code in the language.
The distinction between an object-oriented language and a procedural one can be subtle and hard to grasp, especially with regard to C++, which retains all of C's characteristics and concepts. One way to get at the difference is to say that when programmers code in procedural language they specify actions that do things to data, whereas when they write object-oriented code, they create data objects that can be requested to perform actions on or with regard to themselves.
Thus, a C function receives one or more values as input, transforms or acts upon those values in some way, and returns a result. If the values that are passed include pointers, the contents of data variables may be modified by the function. As the Standard Library routines show, it is likely that the code calling a function will not know, nor need to know, what steps the function takes when it is invoked. However, such matters as the data type of the input parameters and the result code are specified when the function is defined and remain invariable throughout program execution.
Functions are associated with C++ objects as well. But as you will see, the actions performed when an object's function is invoked may automatically differ, perhaps substantially, depending on the specific type of the data structure with which it is associated. This aspect is known as overloading of function names. Overloading is related to a second characteristic of C++, namely the fact that functions can be defined as belonging to C++ data structures--one aspect of the wider language feature known as encapsulation.
In addition to overloading and encapsulation, object-oriented languages also allow you to define new abstract data types (including associated functions) and then derive subsequent data types from them. The notion of a new class of data objects, in addition to the built-in classes such as integer, floating point number, and character, goes beyond the familiar ability to define complex data objects in C. Just as a C data structure that includes, say, an integer element inherits the properties and functions applicable to integers, so too a C++ class that is derived from another class inherits the class' functions and properties. When a specific variable or structure (instance) of that class' type is defined, the class is said to be instantiated.
In the remainder of this chapter, you will look at some of the basic features of C++ in more detail, along with code examples that will provide concrete examples of these concepts. To learn more about the rich capabilities of C++, consult the titles mentioned at the beginning of this chapter.
C++ differs from C in some details apart from the more obvious object-oriented features. Some of these details are fairly superficial, among them
Other differences have to do with advanced concepts such as memory management and the scope of reference for variable and function names. Because the latter features, especially, are used in object-oriented C++ programs, they are worth examining more closely in this short introduction to the language.
The phrase scope of reference is used to discuss how a name in C, C++, or certain other programming languages is interpreted when the language permits more than one instance of a name to occur within a program. Consider the code in Listing 6.10. Here two different functions are defined and then called. Each function has an internal variable called tmp. The tmp that is defined within printnum is local to the printnum function; that is, it can be accessed only by logic within printnum. Similarly, the tmp that is defined within printchar is local to the printchar function. The scope of reference for each tmp variable is limited to the printnum and printchar functions, respectively.
#include <stdio.h> /* I/O function declarations */
void printnum ( int ); /* function declaration */
void printchar ( char ); /* function declaration */
main ()
{
printnum (5); /* print the number 5 */
printchar ("a"); /* print the letter a */
}
/* define the functions called above */
/* void means the function does not return a value */
void printnum (int inputnum)
{
int tmp;
tmp = inputnum;
printf ("%d \n",tmp);
}
void printchar (char inputchar)
{
char tmp;
tmp = inputchar;
printf ("%c \n",tmp)
}
When this program is executed after compilation, it creates the output shown in Listing 6.11.
5 a
Listing 6.12. shows another example of scope of reference. Here you find a global variable tmp--that is, one that is known to the entire program because it is defined within the main function--in addition to the two tmp variables that are local to the printnum and printchar functions.
#include <stdio.h>
void printnum ( int ); /* function declaration */
void printchar ( char ); /* function declaration */
main ()
{
double tmp; /* define a global variable */
tmp = 1.234;
printf ("%e\n",tmp); /* print the value of the global tmp */
printnum (5); /* print the number 5 */
printf ("%e\n",tmp); /* print the value of the global tmp */
printchar ("a"); /* print the letter a */
printf ("%e\n",tmp); /* print the value of the global tmp */
/* define the functions used above */
/* void means the function does not return a value */
void printnum (int inputnum)
{
int tmp;
tmp = inputnum;
printf ("%d \n",tmp);
}
void printchar (char inputchar)
{
char tmp;
tmp = inputchar;
printf ("%c \n",tmp)
}
The global tmp is not modified when the local tmp variables are used within their respective functions, as is shown by the output in Listing 6.13.
1.234 5 1.234 a 1.234
C++ does provide a means to specify the global variable even when a local variable with the same name is in scope. The operator :: prefixed to a variable name always resolves that name to the global instance. Thus, the global tmp variable defined in main in Listing 6.12 could be accessed within the print functions by using the label ::tmp.
Why would a language like C or C++ allow different scopes of reference for the same variable?
The answer to this question is that allowing variable scope of reference also allows functions to be placed into public libraries for other programmers to use. Library functions can be invoked merely by knowing their calling sequences, and no one needs to check to be sure that the programmers didn't use the same local variable names. This capability, in turn, means that library functions can be improved, if necessary, without affecting existing code. This is true whether the library contains application code for reuse or is distributed as the runtime library associated with a compiler.
NOTE: A runtime library is a collection of compiled modules that perform common C, C++, and UNIX functions. The code is written carefully, debugged, and highly optimized. For example, the printf function requires machine instructions to format the various output fields, send them to the standard output device, and check to see that no I/O errors occurred. Because this process takes many machine instructions, repeating that sequence for every printf call in a program would be inefficient. Instead, the developers of the compiler can write a single all-purpose printf function once and place it in the Standard Library. When your program is compiled, the compiler generates calls to these pre-written programs instead of re-creating the logic each time a printf call occurs in the source code.
Variable scope of reference is the language feature that allows you to design small C and C++ programs to perform standalone functions, yet also to combine them into larger utilities as needed. This flexibility is characteristic of UNIX, the first operating system to be built on the C language. As you'll see in the rest of the chapter, variable scope of reference also makes object-oriented programming possible in C++.
Overloading is a technique that allows more than one function to have the same name. In at least two circumstances, you might want to define a new function with the same name as an existing one:
In C, you can reuse a function name as long as the old function name is not within scope. A function name's scope of reference is determined in the same way as a data name's scope: A function that is defined (not just called) within the definition of another function is local to that other function.
When two similar C functions must coexist within the same scope, however, they cannot bear the same name. Instead, you must assign two different names, as with the strcpy and strncpy functions from the Standard Library, each of which copies strings but does so in a slightly different fashion.
C++ gets around this restriction by allowing overloaded function names. That is, the C++ language allows you to reuse function names within the same scope of reference as long as the parameters for the function differ in number or type.
Listing 6.14 shows an example of overloading functions. This program defines and calls two versions of the printvar function, one equivalent to printnum, used previously, and the other to printchar. Listing 6.15 shows the output of this program when it is executed.
#include <stdio.h>
void printvar (int tmp)
{
printf ("%d \n",tmp);
}
void printvar (char tmp)
{
printf ("a \n",tmp);
}
void main ()
{
int numvar;
char charvar;
numvar = 5;
printvar (numvar);
charvar = "a";
printvar (charvar);
}
5 a
Overloading is possible because C++ compilers can determine the format of the arguments sent to the printvar function each time it is called from within main. The compiler substitutes a call to the correct version of the function based on those formats. If the function being overloaded resides in a library or in another module, the associated header file (such as stdio.h above) must be included in this source code module. This header file contains the prototype for the external function, thereby informing the compiler of the parameters and parameter formats used in the external version of the function.
Standard mathematical, logical, and other operators can also be overloaded. This advanced and powerful technique allows you to customize exactly how a standard language feature will operate on specific data structure or at certain points in the code. You must exercise great care when overloading standard operators such as +, MOD, and OR to ensure that the resulting operation functions correctly, is restricted to the appropriate occurrences in the code, and is well documented.
A second feature of C++ that supports object-oriented programming, in addition to overloading, is the capability to associate a function with a particular data structure or format. Such functions may be public (invocable by any code), private (invocable only by other functions within the data structure), or allow limited access.
In C++, you must define data structures using the struct keyword. Such structures become new data types added to the language (within the scope of the structure's definition). Listing 6.16 revisits the structure of Listing 6.3 and adds a display function to print out instances of the license structure. Note the alternative way to designate comments in C++, using a double slash. This double slash tells the compiler to ignore everything that follows, on the given line only.
Also notice that this example uses the C++ character output function cout rather than the C routine printf.
#include iostream.h
// structure = new data type
struct license {
char name[128];
char address[3][128];
int zipcode;
int height, weight, month, day, year;
char license_letter;
int license_number;
void display(void) // there will be a function
 to display license type structures
};
// now define the display function for this data type
void license::display()
{
cout << "Name: " << name;
cout << "Address: " << address(0);
cout << " " << address(1);
cout << " " << address(2) " " <<zipcode;
cout << "Height: " << height " inches";
cout << "Weight: " << weight " lbs";
cout << "Date: " << month "/" << day "/" << year;
cout << "License: " <<license_letter <<license_number;
}
main
{
struct license newlicensee; // define a variable of type license
newlicensee.name = "Joe Smith"; // and initialize it
newlicensee.address(0) = "123 Elm Street";
newlicensee.address(1) = ""
newlicensee.address(2) = "Smalltown, AnyState";
newlicensee.zipcode = "98765";
newlicensee.height = 70;
newlicensee.weight = 165;
license.month = 1;
newlicensee.day = 23;
newlicensee.year = 97;
newlicensee.license_letter = A;
newlicensee.license_number = 567890;
newlicensee.display; // and display this instance of the structure
}
to display license type structures
};
// now define the display function for this data type
void license::display()
{
cout << "Name: " << name;
cout << "Address: " << address(0);
cout << " " << address(1);
cout << " " << address(2) " " <<zipcode;
cout << "Height: " << height " inches";
cout << "Weight: " << weight " lbs";
cout << "Date: " << month "/" << day "/" << year;
cout << "License: " <<license_letter <<license_number;
}
main
{
struct license newlicensee; // define a variable of type license
newlicensee.name = "Joe Smith"; // and initialize it
newlicensee.address(0) = "123 Elm Street";
newlicensee.address(1) = ""
newlicensee.address(2) = "Smalltown, AnyState";
newlicensee.zipcode = "98765";
newlicensee.height = 70;
newlicensee.weight = 165;
license.month = 1;
newlicensee.day = 23;
newlicensee.year = 97;
newlicensee.license_letter = A;
newlicensee.license_number = 567890;
newlicensee.display; // and display this instance of the structure
}
Note that the three references here to the same function. First, the function is prototyped as an element within the structure definition. Second, the function is defined. Because the function definition is valid for all instances of the data type license, the structure's data elements are referenced by the function without naming any instance of the structure. Finally, when a specific instance of license is created, its associated display function is invoked by prefixing the function name with that of the structure instance.
Listing 6.17 shows the output of this program.
Name: Joe Smith
Address: 123 Elm Street
Smalltown, AnyState 98765
Height: 70 inches
Weight: 160 lbs
Date: 1/23/1997
License: A567890
Overloading and the association of functions with data structures lay the groundwork for object-oriented code in C++. Full object-orientation is available through the use of the C++ class feature.
A C++ class extends the idea of data structures with associated functions by binding (or encapsulating) data descriptions and manipulation algorithms into new abstract data types. When classes are defined, the class type and methods are described in the public interface. The class may also have hidden private functions and data members as well.
Class declaration defines a data type and format but does not allocate memory or in any other way create an object of this type. The wider program must declare an instance, or object, of this type to store values in the data elements or to invoke the public class functions. Classes are often placed into libraries for use by many different programs, each of which then declares objects which instantiate that class for use during program execution.
Listing 6.18 illustrates a typical class declaration in C++.
#include <iostream.h>
// declare the Circle class
class Circle {
private:
double radius; // private data member
public:
Circle (rad); // constructor function
~Circle (); // deconstructor function
double area (void); // member function - compute area
};
// constructor function for objects of this class
Circle::Circle(double radius)
{
rad = radius;
}
// deconstructor function for objects of this class
Circle::~Circle()
{
// does nothing
}
// member function to compute the Circle's area
double Circle::area()
{
return rad * rad * 3.141592654;
}
// application program that uses a Circle object
main()
{
Circle mycircle (2); // declare a circle of radius = 2
cout << mycircle.area(): // compute & display its area
}
This example begins by declaring the Circle class. This class has one private member, a floating point element. The class also has several public members, consisting of three functions.
The constructor function of a class is a function called by a program to construct or create an object that is an instance of the class. In the case of the Circle class, the constructor function requires a single parameter, namely the radius of the desired circle. If a constructor function is explicitly defined, it has the same name as the class and does not specify a return value, even of type void.
NOTE: When a C++ program is compiled, the compiler generates calls to the runtime system that allocate sufficient memory each time an object of class Circle comes into scope. For example, an object that is defined within a function is created (and goes into scope) whenever the function is invoked. However, the object's data elements are not initialized unless a constructor function has been defined for the class.
The deconstructor function of a class is a function called by a program to deconstruct an object of the class type. A deconstructor takes no parameters and returns nothing.
NOTE: Under normal circumstances, the memory associated with an object of a given class is released for reuse whenever the object goes out of scope. In such a case, you can omit defining the deconstructor function. However, in advanced applications, or where class assignments cause potential pointer conflicts, explicit deallocation of free-store memory may be necessary.
In addition to the constructor and deconstructor functions, the Circle class contains a public function called area. Programs can call this function to compute the area of circle objects.
The main program in Listing 6.18 shows how you can declare an object. mycircle is declared to be of type Circle and given a radius of 2.
The final statement in this program calls the function to compute the area of mycircle and passes it to the output function for display. Note that the area computation function is identified by a composite name, just as with other functions that are members of C++ data structures outside class definitions. This use underscores the fact that the object mycircle, of type Circle, is asked to execute a function that is a member of itself and with a reference to itself. You could define a Rectangle class that also contains an area function, thereby overloading the area function name with the appropriate algorithm for computing the areas of different kinds of geometric entities.
A final characteristic of object-oriented languages, and of C++, is support for class inheritance and for polymorphism.
You can define new C++ classes (and hence data types) so that they automatically inherit the properties and algorithms associated with the parent class(es). This is done whenever a new class uses any of the standard C data types. The class from which new class definitions are created is called the base class. For example, a structure that includes integer members also inherits all the mathematical functions associated with integers. New classes that are defined in terms of the base classes are called derived classes. The Circle class in Listing 6.18 is a derived class.
Derived classes may be based on more than one base class, in which case the derived class inherits multiple data types and their associated functions. This type is called multiple inheritance.
Because functions can be overloaded, an object declared as a member of a derived class might act differently than an object of the base class type. For example, the class of positive integers might return an error if the program tries to assign a negative number to a class object, although such an assignment would be legal with regard to an object of the base integer type.
This capability of different objects within the same class hierarchy to act differently under the same circumstances is referred to as polymorphism, which is the object-oriented concept that many people have the most difficulty grasping. However, it is also the concept that provides much of the power and elegance of object-oriented design and code. If you're designing an application using predefined graphical user interface (GUI) classes, for example, you are free to ask various window objects to display themselves appropriately without having to concern yourself with how the window color, location, or other display characteristics are handled in each case.
Class inheritance and polymorphism are among the most powerful object-oriented features of C++. Together with the other, less dramatic extensions to C, these features have made possible many of the newest applications and systems capabilities in UNIX today, including GUIs for user terminals and many of the most advanced Internet and World Wide Web technologies, some of which are discussed in the subsequent chapters of this book.
UNIX was built on the C language. C is a platform-independent, compiled, procedural language based on functions and the ability to derive new, programmer-defined data structures.
C++ extends the capabilities of C by providing the necessary features for object-oriented design and code. C++ compilers correctly compile ANSI C code. C++ also provides some features, such as the capability to associate functions with data structures, that do not require the use of full class-based, object-oriented techniques. For these reasons, the C++ language allows existing UNIX programs to migrate toward the adoption of object-orientation over time.
![]()
![]()
![]()
![]()
![]()
©Copyright,
Macmillan Computer Publishing. All rights reserved.
{kind=link}