![]()
![]()
![]()
![]()
![]()
UNIX Unleashed, Internet Edition
![]()
![]()
![]()
![]()
![]()
by Mike Starkenburg
Many people consider server activity to be the true sign of a successful Web site. The more hits you have, the more popular your Web site must be, right? In fact, that's not strictly true, and in the following sections, I explain how the data in your server logs can help you build a better site. In this chapter we'll go over the following:
The primary method for monitoring Web server activity is by analyzing the Web server's access logs. The access log records each HTTP request to the server, including both GET and POST method requests. The access log records successes and failures, and includes a status code for each request. Some servers log "extended" data including browser type and referring site. This data may be in separate logs or stored in the main access log itself.
This data is generally kept in a /logs subdirectory of your server directory. The file is often called access_log, and it can be large--about 1MB per 10,000 entries. The specific directory and name vary depending on your server, and are configurable in the httpd.conf file.
These requests, or hits as they are commonly called, are the basic metric of all Web server usage.
In many organizations, log data is under-utilized or ignored completely. Often, the only person with access to the logging data (and the only person who can interpret the reports) is the Webmaster. In fact, the log data is a gold mine of information for the entire company if properly analyzed and distributed.
One classic use of access logs is to assist in determining which content on a Web site is most effective. By examining the frequency of hits to particular pages, you, as a content developer, can judge the relative popularity of distinct content areas.
Most analysis programs provide lists of the "top ten" and "bottom ten" pages on a site, ranked by total hits. By examining this kind of report, a Web content developer can find out which types of content users are finding helpful or entertaining.
Web sites can have over 50 percent of their hits just to the index page, which isn't much help in determining content effectiveness. Where the user goes next, however, is perhaps one of the most useful pieces of data available from the access logs. Some analysis programs (you explore a few later in the chapter) allow you to examine the most common user "paths" through the site.
CAUTION: Note that for programming and advertising purposes, access logs cannot be considered a completely accurate source. , In the "Log Accuracy" section later in this chapter, we discuss factors that cause overstatement and understatement of access logs.
Using access logs is a quick method of determining overall server load. By benchmarking your system initially and then analyzing the changes in traffic periodically, you can anticipate the need to increase your system capacity.
Each hit in an access log contains the total transfer size (in kilobytes) for that request. By adding the transfer sizes of each hit, you can get an aggregate bandwidth per period of time. This number can be a fairly good indicator of total load over time.
Of course, the best scaling tests separately track system metrics such as CPU usage, disk access, and network interface capacity. (See Unix Unleashed, System Administrator's Edition for a more detailed discussion of this kind of monitoring.) Analyzing access logs, however, is an easy way to get a quick snapshot of the load.
Advertising is becoming one of the primary business models supporting Internet sites. Advertising is generally sold in thousands of impressions, where an impression is one hit on the ad graphic. Accurate tracking of this information has a direct effect on revenue.
Because Web logs are not 100 percent accurate, businesses that are dependent on ad revenue should consider using an ad management system such as NetGravity or Accipiter. These systems manage ad inventory, reliably count impressions, and also count clickthroughs, which are measures of ad effectiveness.
In cases in which ads are used in non-critical applications, access logs may be useful. They may be used to judge the effectiveness of different ads in the same space. Finally, you can use access log analysis to find new pages that may be appropriate for ads.
Although each server can have a different access log format, most popular servers use the common log format. Common log format is used in most servers derived from the NCSA httpd server, including Netscape and Apache.
If your server does not use common log format by default, don't fret. Some servers can be configured to use common log format, and some analyzers process several different log formats. If all else fails, you can write a pre-parser that converts your logs to common log format.
A common log format entry looks like the following:
lust.ops.aol.com - - [02/May/1997:04:14:00 -0500] "GET /index.html HTTP/1.0" 200 1672
In plain English, this log entry says that a user on the machine lust.ops.aol.com requested the page index.html from my server at 4:14 a.m. on May 2. The request was made with the HyperText Transfer Protocol, version 1.0. It was served successfully and was a transfer of 1,672 bytes.
You can split common log entries into fields, where each field is separated by a single space. Broken down by field, this entry represents the following:
Every attempted request is logged in the access log, but not all of them are successful. The following common result codes can help you troubleshoot problems on your site:
| Code | Meaning |
| 2XX | Success. |
| 200 | OK. If your system is working correctly, this code is the most common one found in the log. It signifies that the request was completed without incident. |
| 201 | Created. Successful POST command. |
| 202 | Accepted. Processing request accepted. |
| 203 | Partial information. Returned information may be cached or private. |
| 204 | No response. Script succeeded but did not return a visible result. |
| 3XX | Redirection. |
| 301 | Moved. Newer browsers should automatically link to the new reference. The response contains a new address for the requested page. |
| 302 | Found. Used to indicate that a different URL should be loaded. Often used by CGI scripts to redirect the user to the results of the script. |
| 304 | Not modified. A client can request a page "if-modified-since" a certain time. If the object has not been modified, the server responds with a 304, and the locally cached version of the object can be used. |
| 4XX | Client error. |
| 400 | Bad request. Bad syntax in request. |
| 401 | Unauthorized. Proper authentication required to retrieve object. |
| 402 | Payment required. Proper "charge-to" header required to retrieve object. |
| 403 | Forbidden. No authentication possible. This code sometimes indicates problems with file permissions on the UNIX file system. |
| 404 | Not found. No document matches the URL requested. |
| 5XX | Server error. |
| 500 | Internal error. |
| 501 | Not implemented. |
| 502 | Timed out. |
In addition to logging the basic access information in the common log format, some servers log additional information included in the HTTP headers. Check your server software's documentation to determine whether you have this capability. Note that many servers have this capability but have it disabled by default. A simple change to the httpd.conf file may enable extended logging.
In some server software, extended information is logged as fields tacked on the end of each entry in a common log format file. Other servers maintain separate files for the additional information. The two most common types of extended logs are the referrer log and the user_agent log.
Two important questions not answered by the standard access logs are
To answer these questions, look to your referrer log. This data is often ignored by Webmasters, but it can provide a great deal of useful information.
Referrer data is generated by the client that is connecting to your site and is passed in the HTTP headers for each connection. A referrer log entry contains two pieces of data, as in the following example:
http://www.aol.com/credits.html -> /resume.html
The first URL represents the last page the user requested. The second represents the filename on your server that the user is currently requesting. In this case, the person who requested my resume was most recently looking at the aol.com credits page. When referrer data frequently contains a given Web site, it is likely that a Webmaster has linked to your site.
NOTE: If a site shows up only a few times in your referrer log, that information doesn't necessarily indicate that a link exists from that site to yours. In the preceding example, the user might have been looking at the aol.com page last but manually typed in the URL for my resume. The browser still sends the AOL page as the referrer information because it was the last page the user requested. I can assure you that no link connects http://www.aol.com to my resume.
You can get the data you need out of your referrer log in several ways. Many of the tools I describe in the "Analysis Tools" section of this chapter process your referrer log for you as they process your access logs.
If you specifically want to work with the referrer log, check out RefStats 1.1.1 by Jerry Franz. RefStats is a Perl script that counts and lists referring pages in a clean and organized manner. You can find the script and sample output at
http://www.netimages.com/~snowhare/utilities/refstats.html
When Webmasters design Web sites, they are often faced with a difficult question: Which browser will we develop for? Each browser handles HTML differently, and each supports different scripting languages and accessory programs.
In most cases, you should build your site for the browser most frequently used by your audience. One way to decide which browser to support is to watch industry-wide browser market share reports. For one example, try the following site:
http://www.webtrends.com/products/webtrend/REPORTS/industry/browser/apr97/report.htm
A more accurate method is to examine "user-agent" logs. Most servers log the type of browser used for each request in a file called agent_log. The agent information is passed in HTTP headers, like the referrer data.
There is no formal standard for user-agent strings, but they generally consist of a browser name, a slash, a version number, and additional information in parentheses. Now take a look at some common agents:
Mozilla/2.02 (Win16; I)
The preceding is the classic user-agent string: It denotes a user with a Netscape browser on a Windows 16-bit platform. Mozilla is Netscape's internal pet name for its browser.
Here's another example:
Mozilla/2.0 (compatible; MSIE 3.01; AK; Windows 95)
Now, the preceding string looks like Netscape, but it is actually Microsoft's Internet Explorer 3.01 masquerading as Netscape. Microsoft created this agent to take advantage of early Web sites that delivered two versions of content: one for Netscape users with all the bells and whistles, and a plain one for everyone else.
Now consider this example:
Mozilla/2.0 (Compatible; AOL-IWENG 3.1; Win16)
Here's another imposter. This time, it's the AOL proprietary browser. AOL's browser began life as InternetWorks by BookLink, hence the IWENG name.
The following is yet another example:
Mozilla/3.01 (Macintosh; I; PPC) via proxy gateway CERN-HTTPD/3.0 libwww/2.17
This one is really Netscape 3.01 on a PowerPC Mac. What's interesting about this agent is that the user was behind a Web proxy. The proxy tacked its name onto the actual agent string.
Again, many of the analysis programs discussed in this chapter process user_agent logs as well. If you want a quick way to process just the user_agent file, check out Chuck Musciano's nifty little sed scripts at
http://members.aol.com/htmlguru/agent_log.html
The second type of standard Web server activity log is the error log. The error log records server events, including startup and shutdown messages. The error log also records extended debugging information for each unsuccessful access request.
This data is generally kept in the /logs subdirectory with the access_log. The file is often called error_log. The specific directory and name vary depending on your server, and are configurable in the httpd.conf file.
Most events recorded in the error log are not critical. Depending on your server and configuration, your server may log events like the following:
[02/May/1997:12:11:00 -0500] Error: Cannot access file/usr/people/www/pages/artfile.html. File does not exist.
This message simply means that the requested file could not be found on the disk. The problem could be a bad link, improper permissions settings, or a user could be requesting outdated content.
Some entries in the error log can be useful in debugging CGI scripts. Some servers log anything written by a script to stderr as an error event. By watching your error logs, you can identify failing scripts. Some of the common errors that indicate script failures include
The simplest measure of your server activity is to execute the following command:
wc -l access_log
This command returns a single number that represents the total accesses to your server since the log was created. Unfortunately, this number includes many accesses you might not want to count, including errors and redirects. It also doesn't give you much useful information.
By judicious use of SED, GREP, shell scripting, or piping, you can create a much more interesting output. For example, if you were tracking hits to a certain advertisement graphic, you could use the following:
grep ad1.gif access_log | wc -l
By issuing ever more complex commands, you can begin to gather really useful information about usage on your site. These scripts are time-consuming to write, execute slowly, and have to be revised every time you want to extract a different statistic. Unless you have a specific statistic you need to gather in a certain format, you will probably be better off using one of the many analysis programs on the market. You examine a few of them later in this chapter.
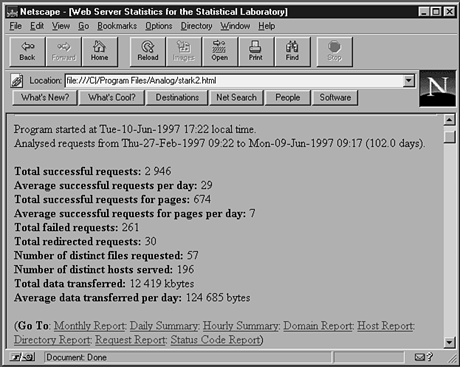
Figure 22.1 shows the general statistics derived from my access log by my favorite analysis program, Analog. I talk at more length about Analog in the "Analysis Tools" section of this chapter. Other tools may give slightly different output, but Analog produces a good variety of basic statistics and is easy to use.
Figure 22.1.
General statistics.
The general statistics section gives a good snapshot of traffic on your server. As you can see in the figure, the analysis program has summarized several categories of requests, including
You might also get average hits per day, total unique hosts or files, and an analysis of the total bytes served.
NOTE: If you plan to use your log analysis for advertising or content programming, be sure you know the difference between hits and impressions. Hits represent all the accesses on your server, whereas impressions represent only the accesses to a specific piece of information or advertisement. Most people count impressions by counting only actual hits to the HTML page containing the content or graphics.
By watching for changes in this information, you can see when you are having unusually high numbers of errors, and you can watch the growth of your traffic overall. Of course, taking this snapshot and comparing the numbers manually every day gets tiresome, so most analysis tools allow some kind of periodic reports.
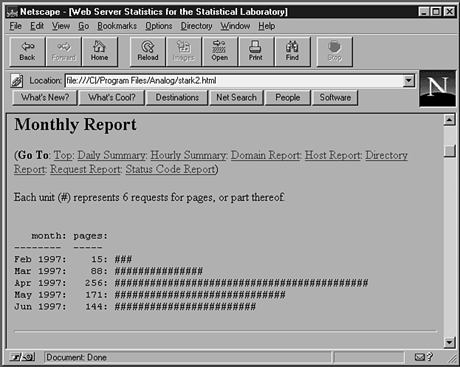
Analysis tools provide a variety of reports that count usage over a specific period of time. Most of these reports count total hits per period, although the more advanced tools allow you to run reports on specific files or groups of files. Each of the periodic reports has a specific use.
Figure 22.2.
Monthly report.
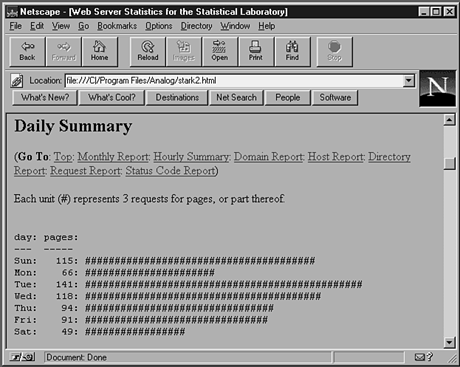
Figure 22.3.
Daily report.
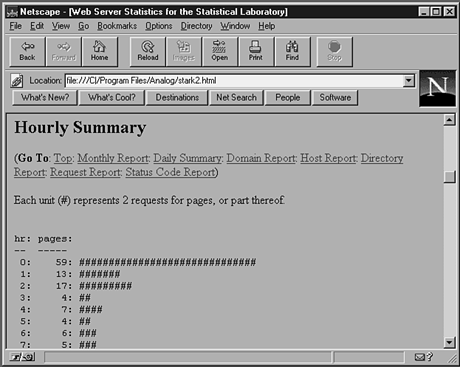
Figure 22.4.
Hourly report.
Some analysis programs also allow you to run reports for specific periods on time in whatever units you may need.
Before you get excited, be informed: In most cases, you cannot get personal demographics information from your Web logs. You can't get users' age, sex, or income level without explicitly asking.
If your friends in marketing would like real demographics on the average Web user, check out the Commercenet/Nielsen Internet user demographics survey athttp://www.commerce.net/nielsen/index.html
You can get the following information out of the basic Web logs:
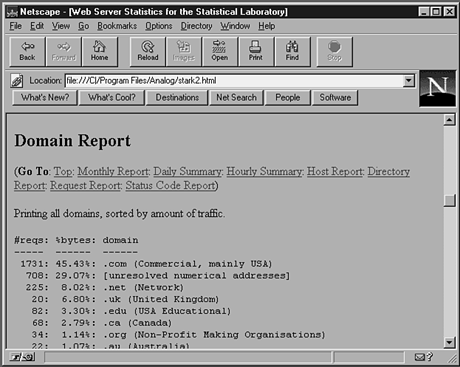
Figure 22.5.
Domain report.
Tip: Many Web servers give you the option either to log the user's IP address or to look up the actual hostname at the time of access. Many analysis programs perform a lookup for you as they analyze the logs. The choice is yours, and the trade-off is speed: Either you have a small delay with every hit as the server does the lookup or a big delay in processing as the analysis program looks up every single address.
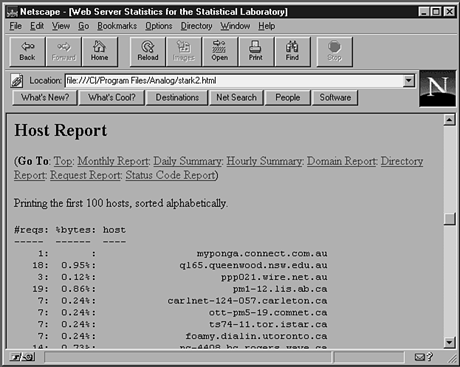
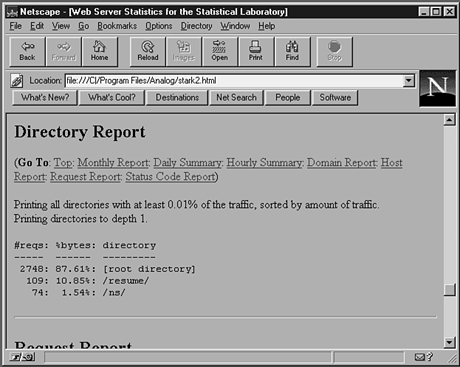
One of the most interesting questions you can ask of your logs is this: What do people look at most on my Web site? Figures 22.6 and 22.7 show the reports that answer this question.
Figure 22.6.
Host report.
Figure 22.7.
Directory report.
The basic reports I've talked about merely summarize the access logs in different ways. Some more advanced analysis methods look for patterns in the log entries. Two useful patterns that the access log entries can produce are user sessions and session paths.
Some advanced analysis programs allow you to try to distinguish unique visits to your site. These programs usually define a session as a series of requests from a specific IP address within a certain period of time. After a session is defined, the program can give you additional information about the session. Over time, you can gather aggregate information that may be useful for marketing and planning, including
Sessioning is not an exact science. If multiple users come from the same IP address during the same period, those hits can't be used for sessioning. Therefore, users from online services that use Web proxies (including AOL and Prodigy) can't be tracked with sessioning. Also, dynamic IP addresses that are frequently reassigned can't be reliably tracked by sessioning. Despite these weaknesses, you may still be able to gain some interesting information from an analysis program that allows sessioning.
If you can identify a specific user session, you can follow that user's path from page to page as he or she navigates through your Web site. Advanced analysis programs look at each session and find the most frequently followed paths. Experienced Webmasters use this data to determine the most popular entry pages, the most popular exit pages, and the most common navigation paths.
Your Web server logs provide a wealth of useful data to Webmasters, marketers, and advertisers. Unfortunately, the raw log by itself is not a reliable source for accurate counts of your site usage. A number of factors can cause the output of reports run on your raw logs to be significantly overstated or understated.
If your log understates usage, it can quickly cause measurable damage to your bottom line. Imagine if you run an advertising-supported Web site, and your ad impressions are 10 percent off? Imagine if you have carefully scaled your Web site to perform well under peak load, as forecasted by your raw logs, only to find that you are under-built by up to 25 percent! In the following sections, I describe some causes of these inaccuracies and ways to mitigate those risks.
The biggest problem that affects your log accuracy is content caching. If a piece of content is cached, it is served to the user from a store, either locally on the user's hard drive or from an ISP's proxy system. When content is served from a cache, often no request is made to your server, so you never see any entry in your logs.
In most cases, caching is a good thing: It improves the user experience, lessens the load on the Net, and even saves you money in hardware and network costs. You might want to optimize your site to take advantage of caching, but before you do, you should consider the effects that caching will have on your log files. In fact, in only a few cases will you want to consider defeating a caching system:
If you want to take advantage of your user's proxy and local cache, you should try to determine what percentage of your hits are understated because of the cache. You can then use this figure as a rule of thumb for future analysis.
Most Web browsers keep a local cache of content and serve out of that cache whenever possible. Some browsers send a special kind of request called a "get-if-modified-since" that, in effect, asks the server whether the document has been updated. If the server finds that the document has been updated, it returns the new document. If it finds that the document is the same, it returns a status code 304. Status code 304 tells the browser to serve the document out of the cache.
TIP: According to FIND/SVP, as much as one third of all Web traffic originates with America Online users. Depending on your audience, a significant proportion of your traffic might be coming from behind AOL's caching system and through its proprietary browser. For the inside scoop on how to best program for that environment, check out AOL's Web site at
The site contains details on AOL's browsers, proxy system, and other useful stuff.
Some browsers support methods of defeating the cache on a page-by-page basis. You should use these methods sparingly; caching is your friend! By inserting the following http headers, you might be able to defeat caching for the pages that follow them:
HTTP 1.0 header: Pragma: no-cache
HTTP 1.0 header: Expires: Thu, 01 Dec 1997 16:00:00 GMT
HTTP 1.0 header: Expires: now
HTTP 1.1 header: Cache-Control: no-cache
HTTP 1.1 header: Cache-Control: no-store
Many corporations and large ISPs, including America Online, use a caching proxy for their members' Web access. Besides the normal security role of a proxy, these servers keep a copy of some content closer to the members. This way, these ISPs can provide faster Web service and significantly ease the load on the Internet.
Proxy caches can be configured to keep content for a certain length of time or until the file reaches a certain age. If you want to ensure that your content is not cached, you can try several things. First, many caching proxies follow the instructions of the expires and cache-control headers listed in the preceding section. In addition, some proxies do not cache any requests that contain cgi-bin or a question mark because these characters usually denote dynamic, script-generated pages.
CAUTION: Each ISP has different "rules" for what is cached and for how long. Some follow all the rules outlined previously, and some follow none. To make things worse, some ISPs occasionally change their caching rules. If you're concerned about your content being held in a proxy cache, you should periodically test to see if your content is cached by that ISP.
As you saw earlier in the chapter, you can analyze your logs manually using a wide variety of text manipulation tools. This kind of analysis gets tedious, however, and is hard to maintain. To get the most useful data from your web server logs, you will probably want to invest the time and money to choose, install, and use a web server analysis tool.
There are literally hundreds of analysis tools on the market, ranging from simple freeware PERL scripts to complicated database-driven applications. Because the market is so new, it's easy to become confused about exactly which features you need for your application. Before you select an analysis tool, be sure you know:
The most important question to ask yourself when evaluating analysis programs is "Exactly what information am I looking for?" If you are only looking for basic access analysis, such as hits over a specific period of time, or basic web demographics, then almost any analysis program will suffice.
As your needs become more sophisticated, you'll need to make sure your package will support advanced analysis features. Generally, advanced features such as pathing and sessioning are only available in commercial packages costing hundreds of dollars.
Analysis programs vary widely in the overall attractiveness of their report output. Almost all programs create HTML files as the primary output format, and many create graphs and tables within those pages. This kind of output is generally acceptable for your own analysis, but falls short for some business applications.
If you intend to distribute your web log reports to clients, partners, or investors, consider using a more advanced package that offers better page layout. Many commercial packages will provide output in document formats (for example, Microsoft Word) with embedded color tables and graphs.
Most analysis programs are designed for the single server website. They expect to read only one log file, and build relative links from only one home page. If your website spans more than one server, or you manage several different websites, you may want to consider getting an advanced analysis package.
Analysis programs which have "enterprise support" can handle multiple log files, and can build reports which represent multiple websites. They allow you to group websites to present consolidated data across several servers. This kind of support, unfortunately, is mostly only found in the most expensive packages.
Not all analysis programs are available for all UNIX versions, and many are available only for Windows NT. If you are going to be running your analysis on the same machine as your web server, you need to ensure that your analysis program is compatible with your UNIX version.
You don't necessarily have to run your analysis program on the same machine as your webserver. In fact, it may be desirable to have a different machine dedicated to this task. Log analysis can have a heavy impact on your machine performance, in both CPU utilization and disk usage. If you are going to have a machine specifically for log analysis, then you can get the hardware to support the software which has the features you like.
As your access logs quickly grow to several megabytes in size, analysis speed becomes an issue. Check to see how fast your analysis program claims to run against larger files: Most vendors will give you a metric measured in "megabytes processed per minute."
Log processing speed does not always grow linearly: As your logs get bigger, some analysis programs will get progressively slower. Before you invest in an expensive processing program, test the performance on some real logs--and be aware that some of the fastest programs are freeware.
Prices for analysis programs vary widely, but they tend to fall into one of three categories: freeware tools, single-site commercial products, and enterprise commercial packages.
The quickest way to get into web analysis is to download one of the very capable pieces of freeware on the market. These programs can quickly digest your access logs and give you very usable information immediately. In addition, source is often available for you to add your own special touches. They often lack some of the advanced features of the commercial tools, but try these out before you spend hundreds (or thousands) of dollars on another tool:
TIP: An extremely interesting writeup on the comparative performance of several freeware tools (complete with links to the homepage of each tool) is available at:www.uu.se/software/getstats/performance.html
Most serious business applications will eventually require a commercial analysis tool. Besides being more robust and feature rich, these products include upgrades and technical support that most MIS departments need. Prices on these packages can range from $295 to $5,000 and higher, depending on your installation. Many of the products are available for a free trial download on their website so you can try before you buy.
In this chapter, you learned about tracking Web server usage. This data, which is primarily stored in the access and error logs, provides information that helps you scale, program, and advertise on your Web site.
The access log tracks each attempt request and provides you with the bulk of your server activity information. The extended logs help you track which browsers were most used to access your site and which sites passed the most traffic to you.
Basic analysis includes counting the entries in the access log in a number of different ways. The simplest statistics you can gather are summaries of different types of accesses, including successes and failures. Looking at traffic over time, in hourly, daily, and monthly reports, is also useful. Finally, the logs provide you with limited "demographic" information about your visitors, such as which country they are in and whether they are from commercial or educational institutions.
Advanced analysis involves looking for patterns in the accesses. Sessioning is the process of identifying unique visits and determining the duration and character of the visit. Pathing is looking for the most common navigational paths users took during their visit.
Unfortunately, the access logs are not necessarily reliable sources of data. Several factors can affect your log's accuracy, most importantly caching. Local caching and proxy caching can both cause your log numbers to be understated.
Finally, you learned about several tools that are available to assist you in analyzing your server activity. Many tools are freely available over the Net, whereas others are commercial products that include support and upgrades. Some companies download, audit, and process your logs for you for a monthly fee.
![]()
![]()
![]()
![]()
![]()
©Copyright,
Macmillan Computer Publishing. All rights reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}