Inside the HBOOK division the various data elements are
stored as a ZEBRA data structure, one for each ``identifier''.
In fact all identifiers (histogram or Ntuple numbers)
are stored in an ordered array in a ZEBRA
bank and access to the information associated with the HBOOK data
is via the reference link at the same offset as the
identifier in the data part of the bank. The data structure for
a given element depends on its characteristics.
In any case the top bank for a given element contains the
title and other constants, while the data themselves are
stored in another bank hanging from the previous one. Sometimes
other banks are created, e.g. for automatic binning,
for storing the limits of the elements of a Ntuple and,
when a Ntuple is kept in memory, for containing the overflow
of the data, for projections, slices and
bands in the 2-dim case of for containing the errors
associated to a bin. This means that each HBOOK identifier
has a whole set of attributes associated with its
existence, and when a histogram or Ntuple is written to backup
store and later reread, the complete data structure, containing
all characteristics and attributes are retrieved.
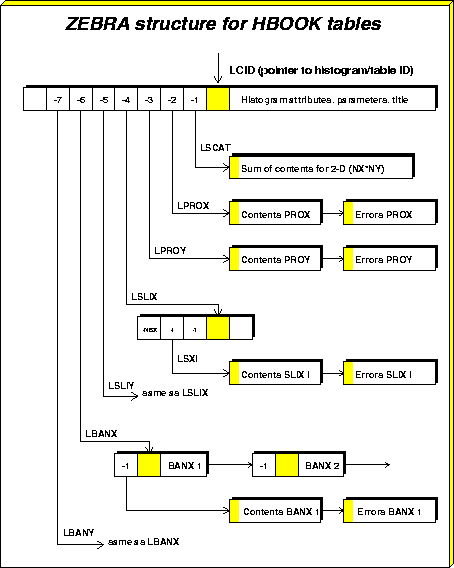
Figure ![]() shows
the ZEBRA data structure for a two-dimensional histogram.
The precise layout of this bank should be of no concern to the
user. It is only shown here as an example of the underlying ZEBRA structure
of HBOOK. Note the use of the data part of the bank for
storing attributes (e.g. title, number of bins, number of entries) as
well as of the link part for storing the addresses to access the
associated data points (scatter plot contents, X and Y projections,
slices and bands and their associated errors).
shows
the ZEBRA data structure for a two-dimensional histogram.
The precise layout of this bank should be of no concern to the
user. It is only shown here as an example of the underlying ZEBRA structure
of HBOOK. Note the use of the data part of the bank for
storing attributes (e.g. title, number of bins, number of entries) as
well as of the link part for storing the addresses to access the
associated data points (scatter plot contents, X and Y projections,
slices and bands and their associated errors).
The ZEBRA data structure used for two-dimensional histograms